cockroachdb设计翻译
提供一个cockroachdb的设计说明翻译 ,原文
About
This document is an updated version of the original design documents by Spencer Kimball from early 2014.
本文是对Spencer Kimball于2014年初写的原始设计文档的更新版。
Overview
Cockroach is a distributed key:value datastore (SQL and structured data layers of cockroach have yet to be defined) which supports ACID transactional semantics and versioned values as first-class features. The primary design goal is global consistency and survivability, hence the name. Cockroach aims to tolerate disk, machine, rack, and even datacenter failures with minimal latency disruption and no manual intervention. Cockroach nodes are symmetric; a design goal is homogeneous deployment (one binary) with minimal configuration.
Cockroach 是一个以支持 ACID事务 和 多版本值 为首要特性的分布式 Key:Value 数据库(SQL和结构化数据层的cockroach还没有被定义)。 Cockroach 的第一设计目标是 全球一致性和可靠性 ,就像它的名字一样。Cockroach目标是在无人工干预的情况下,以极小的中断时间容忍磁盘,主机,机架甚至 数据中心失效 。 Cockroach的节点是对等的;其中一个设计目标是以最少配置实现 无差别部署 .
Cockroach implements a single, monolithic sorted map from key to
value where both keys and values are byte strings (not unicode).
Cockroach scales linearly (theoretically up to 4 exabytes (4E) of
logical data). The map is composed of one or more ranges and each range
is backed by data stored in RocksDB (a
variant of LevelDB), and is replicated to a total of three or more
cockroach servers. Ranges are defined by start and end keys. Ranges are
merged and split to maintain total byte size within a globally
configurable min/max size interval. Range sizes default to target 64M in
order to facilitate quick splits and merges and to distribute load at
hotspots within a key range. Range replicas are intended to be located
in disparate datacenters for survivability (e.g. { US-East, US-West,
Japan }, { Ireland, US-East, US-West}, { Ireland, US-East, US-West,
Japan, Australia }).
Cockroach 实现了一个 单一的全局sorted map,其key 和 value都是二进制串。Cockroach 是 线性扩展 的,理论上支持4E字节(4096PB,4096*1024TB)的数据。
此Map由一个或者多个range组成,每个range都通过RocksDB(一种优化版的LevelDB)存储在磁盘里。并且每个range都被复制到至少3个Cockroach Server上。
Range是由一个Key范围区间来定义的。Range会被合并或者切分成固定的大小,此大小由一个全局配置的min-max区间设定的。Range的大小默认是 64M,这有利于range的快速切分与合并 ,并且利于在一个热点range里
分配负载。range副本旨在被存放在不同的数据中心以保证存活性。
Single mutations to ranges are mediated via an instance of a distributed consensus algorithm to ensure consistency. We’ve chosen to use the Raft consensus algorithm; all consensus state is stored in RocksDB.
对range的单一修改会通过Raft这个分布式一致性算法来保证数据一致性。所有的一致性状态都保存在RocksDB里。
A single logical mutation may affect multiple key/value pairs. Logical mutations have ACID transactional semantics. If all keys affected by a logical mutation fall within the same range, atomicity and consistency are guaranteed by Raft; this is the fast commit path. Otherwise, a non-locking distributed commit protocol is employed between affected ranges.
一个逻辑修改可能会影响到多个key:value对。逻辑修改具备ACID事务语义。如果一个逻辑修改影响的所有的key都位于同一个range,由Raft来保证原子性和一致性,这就是 fast commit path。 否则,采用 non-locking distributed commit 协议来修改被影响的range.
Cockroach provides snapshot isolation (SI) and serializable snapshot isolation (SSI) semantics, allowing externally consistent, lock-free reads and writes–both from a historical snapshot timestamp and from the current wall clock time. SI provides lock-free reads and writes but still allows write skew. SSI eliminates write skew, but introduces a performance hit in the case of a contentious system. SSI is the default isolation; clients must consciously decide to trade correctness for performance. Cockroach implements a limited form of linearizability, providing ordering for any observer or chain of observers.
Cockroach 提供快照隔离 (SI) 和 串行快照隔离 (SSI) 语义,此语义允许 外部一致性、无锁读写 。 两者都基于历史快照时间戳和当前时间。SI提供无锁读写但是会有写偏序问题(由于每个事务在更新过程中无法看到其他事务的更改的结果,导致各个事务提交之后的最终结果违反了一致性); SSI消除了写偏序,但在有争议系统的某些场景下会损失性能。SSI是默认的隔离机制。客户端必须有意识的处理好正确性和高效性。Cockroach以有限线性化来支持任意顺序的观察者和观察者链。
Similar to Spanner directories, Cockroach allows configuration of arbitrary zones of data. This allows replication factor, storage device type, and/or datacenter location to be chosen to optimize performance and/or availability. Unlike Spanner, zones are monolithic and don’t allow movement of fine grained data on the level of entity groups.
类似于Spanner的目录,Cockroach可以配置任意Zone的数据。可以设置复制因子, 存储设备类型,或者数据中心位置来适应不同的性能和可用性要求。与Spanner不同的是,zones是单片的,不允许在实体group层面进行细粒度的移动。
Architecture
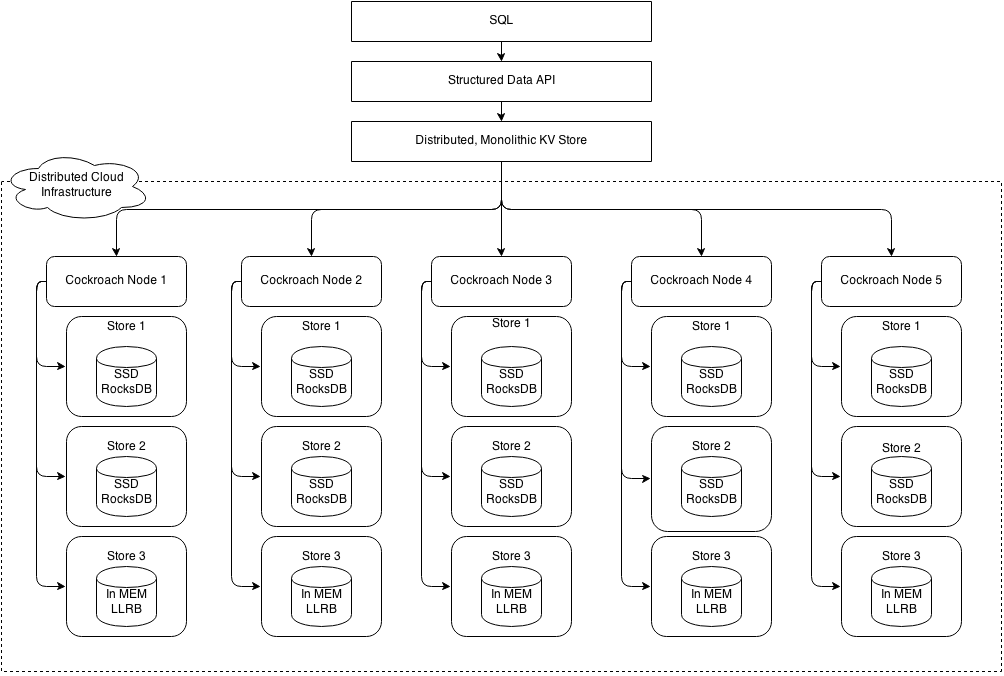
Cockroach implements a layered architecture. The highest level of abstraction is the SQL layer (currently unspecified in this document). It depends directly on the structured data API, which provides familiar relational concepts such as schemas, tables, columns, and indexes. The structured data API in turn depends on the distributed key value store, which handles the details of range addressing to provide the abstraction of a single, monolithic key value store. The distributed KV store communicates with any number of physical cockroach nodes. Each node contains one or more stores, one per physical device.
Cockroach 采用层级架构。最顶层是SQL层(目前本文档中未定义),它直接依赖于 structured data API,来提供熟悉的相关概念,如架构、表、列和索引。 structured data API 反过来取决于 distributed key value store ,来处理range地址的细节,以提供抽象一个单一的,整体的键值存储。distributed key value store 在任意物理cockroach节点间通信。每个物理节点包含一个或多个store。
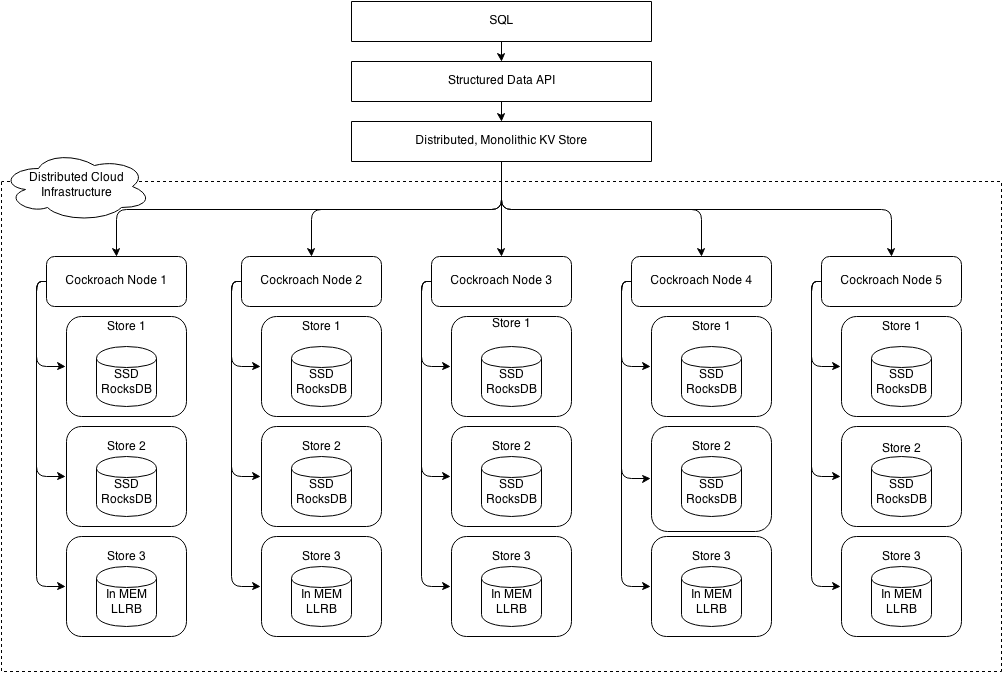
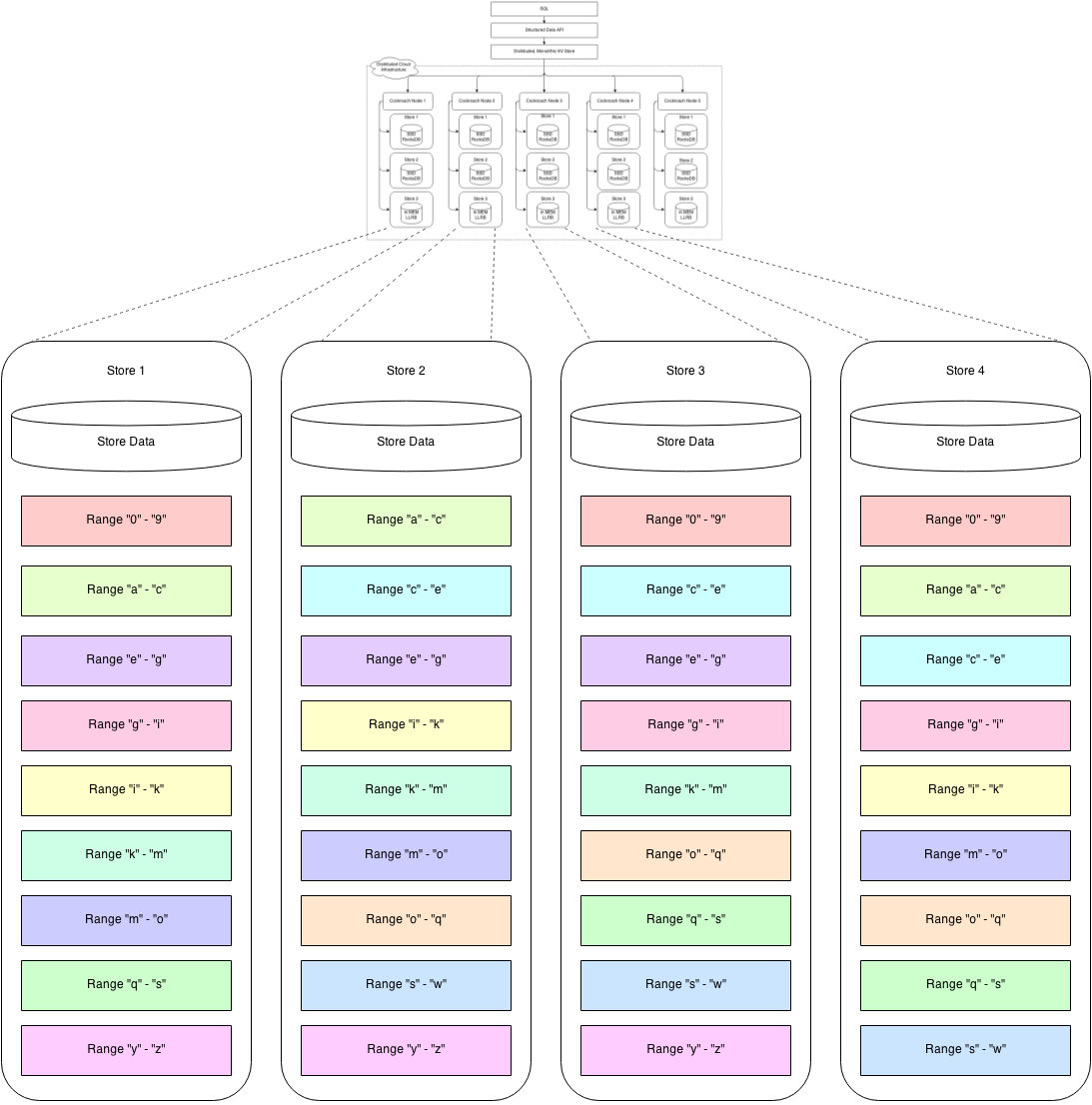
Each store contains potentially many ranges, the lowest-level unit of key-value data. Ranges are replicated using the Raft consensus protocol. The diagram below is a blown up version of stores from four of the five nodes in the previous diagram. Each range is replicated three ways using raft. The color coding shows associated range replicas.
每一个store都可能包含很多range. range是最底层的key:value数据单元。Ranges通过Raft一致性协议进行复制。下图是上一张图中5个节点其中4个节点的store示意图。每个range都使用Raft协议复制3份。 相同颜色表示是相同的range副本。
Each physical node exports a RoachNode service. Each RoachNode exports one or more key ranges. RoachNodes are symmetric. Each has the same binary and assumes identical roles.
每一个物理节点都包含一个RoachNode服务,每个RoachNode服务都包含多个key range. 每个RoachNode是对等的。每个 RoachNode都有相同的二进制数据和相同的角色.
Nodes and the ranges they provide access to can be arranged with various physical network topologies to make trade offs between reliability and performance. For example, a triplicated (3-way replica) range could have each replica located on different:
节点和它所提供的可访问range可以设置各种物理网络拓扑结构,使之兼顾可靠性和性能。比如一个range的三份副本可以位于不同的位置:
- 一个server上的不同磁盘以容忍磁盘失效。
- 一个机架的不同server上,以容忍server失效。
- 一个数据中心的不同机架上,以容忍机架掉电,或者网络故障
-
甚至不同的数据中心以容忍大范围的网络故障或者电力故障
- disks within a server to tolerate disk failures.
- servers within a rack to tolerate server failures.
- servers on different racks within a datacenter to tolerate rack power/network failures.
- servers in different datacenters to tolerate large scale network or power outages.
Up to F failures can be tolerated, where the total number of replicas N = 2F + 1 (e.g. with 3x replication, one failure can be tolerated; with 5x replication, two failures, and so on).
假如总的副本数是 N = 2F + 1 ,则最高容忍 F 个失败(以3个副本来说,可容忍一个失效;5个副本则可容忍2个失效,等等)。
Cockroach ClientRoachNode
In order to support diverse client usage, Cockroach clients connect to any node via HTTPS using protocol buffers or JSON. The connected node proxies involved client work including key lookups and write buffering.
为了支持不同的客户端使用,Cockroach客户端可使用protocol buffers 或者 JSON通过HTTPS连接到任意节点上去。 被连接的节点代理客户端参与工作,包括key查找和写入缓冲。
Keys
Cockroach keys are arbitrary byte arrays. If textual data is used in
keys, utf8 encoding is recommended (this helps for cleaner display of
values in debugging tools). User-supplied keys are encoded using an
ordered code. System keys are either prefixed with null characters (\0
or \0\0) for system tables, or take the form of
<user-key><system-suffix> to sort user-key-range specific system
keys immediately after the user keys they refer to. Null characters are
used in system key prefixes to guarantee that they sort first.
Cockroach keys可以是任意byte数组。如果使用文本数据做为key,建议使用utf-8进行编码(这将有利于在在调试工具中显示)。
Versioned Values
Cockroach maintains historical versions of values by storing them with associated commit timestamps. Reads and scans can specify a snapshot time to return the most recent writes prior to the snapshot timestamp. Older versions of values are garbage collected by the system during compaction according to a user-specified expiration interval. In order to support long-running scans (e.g. for MapReduce), all versions have a minimum expiration.
Cockroach通过保存commit时间戳来保存多历史版本的值。可以通过指定快照时间来读取和扫描此时间戳之前最近一次写入的数据。 根据用户指定的过期时间间隔,当系统compaction时,旧版本的数据会被系统垃圾回收掉。为了支持长时间的数据扫描,所有的版本都有一个最小过期时间。
Versioned values are supported via modifications to RocksDB to record commit timestamps and GC expirations per key.
多版本值是通过修改每个key的rocksdb记录的提交时间戳和GC到期时来实现的。
Each range maintains a small (i.e. latest 10s of read timestamps), in-memory cache from key to the latest timestamp at which the key was read. This read timestamp cache is updated every time a key is read. The cache’s entries are evicted oldest timestamp first, updating the low water mark of the cache appropriately. If a new range replica leader is elected, it sets the low water mark for the cache to the current wall time + ε (ε = 99th percentile clock skew).
每个range都会保持一个小的内存缓存,缓存中记录着读取key时的最新时间戳,每当key被读取时都会更新这个缓存。最老时间戳的缓存条目会被删除,并适当的更新缓存低水位标记。 如果一个新的range副本leader选举出来,会将缓存的低水位标记设置为当前时间 + ε (ε = 99%时钟漂移)
Lock-Free Distributed Transactions
Cockroach provides distributed transactions without locks. Cockroach transactions support two isolation levels:
Cockroach提供无锁的分布式事务,Cockroach事务支持两种隔离级别:
- snapshot isolation (SI) and
- serializable snapshot isolation (SSI).
SI is simple to implement, highly performant, and correct for all but a handful of anomalous conditions (e.g. write skew). SSI requires just a touch more complexity, is still highly performant (less so with contention), and has no anomalous conditions. Cockroach’s SSI implementation is based on ideas from the literature and some possibly novel insights.
SI 比较简单,容易实现,并且性能很高,正确性也不错(除了极少数情况,如写偏序)。SSI 更为复杂,性能也很高(但随连接数增多而降低),并且没有异常情况会导致错误结果。 Cockroach的SSI实现是基于一些文献的想法和一些可能是完全创建新的想法。
SSI is the default level, with SI provided for application developers who are certain enough of their need for performance and the absence of write skew conditions to consciously elect to use it. In a lightly contended system, our implementation of SSI is just as performant as SI, requiring no locking or additional writes. With contention, our implementation of SSI still requires no locking, but will end up aborting more transactions. Cockroach’s SI and SSI implementations prevent starvation scenarios even for arbitrarily long transactions.
SSI 是默认的隔离级别。如果应用开发人员需要追求更高的性能,并且确定没有写偏序的场景下,则可使用 SI级别。在并发竞争较小的系统中,我们的SSI实现在性能上已经与SI持平,不需 要锁和附加写。 在高竞争场景时,SSI实现仍无须锁,但会中止正多的事务。Cockroach的SI和SSI的实现即使对于任意长的事务都可以防止饥饿情况发生。
See the Cahill paper for one possible implementation of SSI. This is another great paper. For a discussion of SSI implemented by preventing read-write conflicts (in contrast to detecting them, called write-snapshot isolation), see the Yabandeh paper, which is the source of much inspiration for Cockroach’s SSI.
可参见Cahill paper 的SSI实现。还有这个great paper. 关于SSI防止读写冲突的实现的讨论,可以看 这个Yabandeh paper, Cockroach的SSI实现灵感就来自于此。
Each Cockroach transaction is assigned a random priority and a “candidate timestamp” at start. The candidate timestamp is the provisional timestamp at which the transaction will commit, and is chosen as the current clock time of the node coordinating the transaction. This means that a transaction without conflicts will usually commit with a timestamp that, in absolute time, precedes the actual work done by that transaction.
每一个Cockroach事务一开始都会分配一个随机优先级和 “候选人时间戳” ,在事务未提交时,候选人时间戳是一个临时的时间戳,取自处理该事务的节点的当前时间。 这就意味着,在没有冲突的情况下,此时间戳在绝对时间上将先于事务结束的时间。
In the course of coordinating a transaction between one or more distributed nodes, the candidate timestamp may be increased, but will never be decreased. The core difference between the two isolation levels SI and SSI is that the former allows the transaction’s candidate timestamp to increase and the latter does not.
在一个事务跨多个节点的情况下,候选人时间戳只能增长,不能后退。SI 和 SSI 两个隔离级别的核心不同点在于前者允许事务的候选人时间戳增长,而后者不允许。
Hybrid Logical Clock 混合逻辑时钟
Each cockroach node maintains a hybrid logical clock (HLC) as discussed in the Hybrid Logical Clock paper. HLC time uses timestamps which are composed of a physical component (thought of as and always close to local wall time) and a logical component (used to distinguish between events with the same physical component). It allows us to track causality for related events similar to vector clocks, but with less overhead. In practice, it works much like other logical clocks: When events are received by a node, it informs the local HLC about the timestamp supplied with the event by the sender, and when events are sent a timestamp generated by the local HLC is attached.
每一个cockroach都维持一个混合逻辑时钟(HLC) ,相关的论文Hybrid Logical Clock paper. 混合逻辑时钟将Logical Clock和物理时钟(wall time)联系起来,它使我们能够以较少的开销跟踪相关事件的因果关系,类似于矢量时钟。但在实践中,它更像是一个逻辑时钟: 当一个节点接收到一个事件,它告知本地的HLC一个此事件发送者的时间戳,这里不会翻了
For a more in depth description of HLC please read the paper. Our implementation is here.
关于混合逻辑时钟(HLC)更深入的介绍请读 这里.
Cockroach picks a Timestamp for a transaction using HLC time. Throughout this document, timestamp always refers to the HLC time which is a singleton on each node. The HLC is updated by every read/write event on the node, and the HLC time >= wall time. A read/write timestamp received in a cockroach request from another node is not only used to version the operation, but also updates the HLC on the node. This is useful in guaranteeing that all data read/written on a node is at a timestamp < next HLC time.
Cockroach 使用HLC 获取一个事务的时间戳。 本文提及的所有 时间戳 都指的是HLC时间,HLC时间在每个节点上是都是单一的。 HLC由节点上的每个读写事件进行更新, 并且HLC 时间总是大于等于( >= )现实时间。 从来自另一个cockroach节点的读写请求里获取的时间戳并不仅仅用来给操作打版本标识, 同时也会更新本节点的HLC。这样的设计可以保证在一个节点上,所有的数据读写时间都小于下一个HLC时间。
Transaction execution flow
Transactions are executed in two phases:
事务执行分为两个阶段:
-
Start the transaction by writing a new entry to the system transaction table (keys prefixed by \0tx) with state “PENDING”. In parallel write an “intent” value for each datum being written as part of the transaction. These are normal MVCC values, with the addition of a special flag (i.e. “intent”) indicating that the value may be committed after the transaction itself commits. In addition, the transaction id (unique and chosen at tx start time by client) is stored with intent values. The tx id is used to refer to the transaction table when there are conflicts and to make tie-breaking decisions on ordering between identical timestamps. Each node returns the timestamp used for the write (which is the original candidate timestamp in the absence of read/write conflicts); the client selects the maximum from amongst all write timestamps as the final commit timestamp.
-
开始一个事务,向系统事务表(key以\0tx为前缀)新写一个记录,状态是“PENDING”。并行为每一个数据写一个“intent”值,作为事务的一部分。 这些都是普通的 MVCC (多版本并发控制)值,通过附加的特殊flag来表明这个值将在事务本身提交以后被提交。此外,事务ID (由客户端选择的一个唯一的事务开始时间)也和“intent”值一起保存。 当有事务冲突时,事务ID用来引用对应的事务表,和在相同的时间戳之间按顺序做出打破平局的决策。每个节点返回用于写入的时间戳(这是在没有读/写冲突时的原始候选人时间戳); 客户端在所有写时间戳中选择最大的作为最终提交时间戳。
-
Commit the transaction by updating its entry in the system transaction table (keys prefixed by \0tx). The value of the commit entry contains the candidate timestamp (increased as necessary to accommodate any latest read timestamps). Note that the transaction is considered fully committed at this point and control may be returned to the client.
In the case of an SI transaction, a commit timestamp which was increased to accommodate concurrent readers is perfectly acceptable and the commit may continue. For SSI transactions, however, a gap between candidate and commit timestamps necessitates transaction restart (note: restart is different than abort–see below).
After the transaction is committed, all written intents are upgraded in parallel by removing the “intent” flag. The transaction is considered fully committed before this step and does not wait for it to return control to the transaction coordinator.
In the absence of conflicts, this is the end. Nothing else is necessary to ensure the correctness of the system.
- 提交一个事务,更新系统事务表(key以\0tx为前缀)中对应的记录。 提交记录中包含对应的候选人时间戳(必要时会增加,以适应任何新的阅读时间戳)。请注意此时事务 已被认为是完全提交了,控制被重新交给客户端。在SI事务的场景中,增加提交时间戳以适应当前的读取者是完全可以接受的,事务将继续提交。 然而对于SSI事务,候选人时间戳与提交时间戳之间有差距则必须重新开始事务(注:事务重启和中止不同,下面会讲)。 事务提交后,所有的预写操作都会被并行的移除“intents”标识,在此完成之前,事务就已被认为是完全提交了,并且不会等待它把控制交返给事务协调者。
在没有冲突时,事务就结束了。不需要再做什么就已经能保证系统正确性了。
Conflict Resolution
Things get more interesting when a reader or writer encounters an intent record or newly-committed value in a location that it needs to read or write. This is a conflict, usually causing either of the transactions to abort or restart depending on the type of conflict.
当一个读事务与一个写事务同时作用于同一个记录,或者新提交的值正好位于它要读或写的记录上,事情就变得很有趣了,这就是一个冲突。通常根据不同的冲突类型会造成其中一个事务中止或者重启。
Transaction restart:
This is the usual (and more efficient) type of behaviour and is used except when the transaction was aborted (for instance by another transaction). In effect, that reduces to two cases; the first being the one outlined above: An SSI transaction that finds upon attempting to commit that its commit timestamp has been pushed. The second case involves a transaction actively encountering a conflict, that is, one of its readers or writers encounter data that necessitate conflict resolution (see transaction interactions below).
除非事务被另一个事务中止,事务重启通常是相对高效的一个行为类型。从影响来说,可以归纳成两种场景: 第一个是上面提到的:一个SSI事务发现它正在提交一个已经被推送过的事务。 第二种场景是涉及到一个事务积极地面对一个冲突:一个读事务或者写事务操作的数据是必须要解决冲突的。(请看下面的交叉事务)
When a transaction restarts, it changes its priority and/or moves its timestamp forward depending on data tied to the conflict, and begins anew reusing the same tx id. The prior run of the transaction might have written some write intents, which need to be deleted before the transaction commits, so as to not be included as part of the transaction. These stale write intent deletions are done during the reexecution of the transaction, either implicitly, through writing new intents to the same keys as part of the reexecution of the transaction, or explicitly, by cleaning up stale intents that are not part of the reexecution of the transaction. Since most transactions will end up writing to the same keys, the explicit cleanup run just before committing the transaction is usually a NOOP.
当一个事务重启时,它的优先级会改变,或者根据与之冲突的数据把它的时间戳向前移动,并重用之前的事务ID. 由于之前的事务可能已经提交了一些尚未提交的预写操作,这些预写的数据需要删除掉, 以避免被新的事务包含进来。在新事物重新执行前要清除这些预写,可以隐式的,通过对新事务中相同key的预写来清除;或者显式清除那些在新事务不存在的预写。 因为大多数的事务都会预写相同的key,所以在提交事务之前,显式清除操作通常什么都不做。
Transaction abort:
This is the case in which a transaction, upon reading its transaction table entry, finds that it has been aborted. In this case, the transaction can not reuse its intents; it returns control to the client before cleaning them up (other readers and writers would clean up dangling intents as they encounter them) but will make an effort to clean up after itself. The next attempt (if applicable) then runs as a new transaction with a new tx id.
事务中止是当一个事务在读它的事务表记录时,发现它被中止了。这种情况,事物不能使用它所有的intents。事物会在这些intents被清除前返回控制权给客户端(其它的读事务和写事务 会清除掉这些无主的intents),之后也会努力清除自已。下一次尝试(如果适用)使用新的事务ID开启一个新事务。
Transaction interactions:
There are several scenarios in which transactions interact:
有以下几种交叉事务场景:
-
Reader encounters write intent or value with newer timestamp far enough in the future: This is not a conflict. The reader is free to proceed; after all, it will be reading an older version of the value and so does not conflict. Recall that the write intent may be committed with a later timestamp than its candidate; it will never commit with an earlier one. Side note: if a SI transaction reader finds an intent with a newer timestamp which the reader’s own transaction has written, the reader always returns that intent’s value.
-
读事务遇到一个预写或者带有一个足够新的将来的时间戳的值:这并不是一个冲突。不须要特殊处理,因为随后它会读取一个旧版本的数据。 回想一下,预写操作将以一个比候选者更大的时间戳提交事务;永远也不可能比候选者时间小。边注:如果一个SI的读事务发现一个intent具有比自己更新的时间戳,则总是 返回新intent的值。
-
Reader encounters write intent or value with newer timestamp in the near future: In this case, we have to be careful. The newer intent may, in absolute terms, have happened in our read’s past if the clock of the writer is ahead of the node serving the values. In that case, we would need to take this value into account, but we just don’t know. Hence the transaction restarts, using instead a future timestamp (but remembering a maximum timestamp used to limit the uncertainty window to the maximum clock skew). In fact, this is optimized further; see the details under “choosing a time stamp” below.
-
读事务遇到一个预写或者带有一个稍新的将来的时间戳的值:这种情况,我们就得小心了。 如果写事务的时钟比接收此value的节点的时钟早,新的intent很有可能发生在读之前。这种情况下,我们可能需要考虑这个值,但是目前无法判断。 因此要使用一个将来的时间戳重启事务(但是记得使用一个最大时间戳将不确定窗口限制到最大时钟偏差)。事实上,这是下一步优化。
-
Reader encounters write intent with older timestamp: the reader must follow the intent’s transaction id to the transaction table. If the transaction has already been committed, then the reader can just read the value. If the write transaction has not yet been committed, then the reader has two options. If the write conflict is from an SI transaction, the reader can push that transaction’s commit timestamp into the future (and consequently not have to read it). This is simple to do: the reader just updates the transaction’s commit timestamp to indicate that when/if the transaction does commit, it should use a timestamp at least as high. However, if the write conflict is from an SSI transaction, the reader must compare priorities. If the reader has the higher priority, it pushes the transaction’s commit timestamp (that transaction will then notice its timestamp has been pushed, and restart). If it has the lower or same priority, it retries itself using as a new priority
max(new random priority, conflicting txn’s priority - 1). -
** 读事务遇到一个早前的预写 ** :读事务必须跟踪这个intent在事务表中的事务ID。 如果事务已经提交过了,则可直接读取数据。反之尚未提交,则有两种选择: 如果写冲突来自一个SI事务,读事务可以 将此事务的提交时间戳延后(因此也不必去读它)。比较简单的做法是:读事务在事务提交时更新一下事务时间戳即可,当然,至少要使用一个更晚的时间戳。 但如果这是一个SSI事务,读事务就必须比较优先级。如里读有更高的优先级,就直接推送它的事务时间戳(此事务稍后会因时间戳已被推送而重启)。如果读事务的优先级低于或等于写的, 则使用新的优先级
max(new random priority, conflicting txn’s priority - 1)重试. -
Writer encounters uncommitted write intent: If the other write intent has been written by a transaction with a lower priority, the writer aborts the conflicting transaction. If the write intent has a higher or equal priority the transaction retries, using as a new priority max(new random priority, conflicting txn’s priority - 1); the retry occurs after a short, randomized backoff interval.
-
写事务遇到另一个事务的预写:如果预写来自另一个优先级更低事务,此事务会中止与之冲突的事务。反之另一个事务的优先级更高,或者相同,此事务使用新的优先级 max(new random priority, conflicting txn’s priority - 1) 在随机延迟一点时间后重试。
-
Writer encounters newer committed value: The committed value could also be an unresolved write intent made by a transaction that has already committed. The transaction restarts. On restart, the same priority is reused, but the candidate timestamp is moved forward to the encountered value’s timestamp.
-
写事务遇到新的已提交的值: 这个已提交的值有可能是一个已提交事务产生的无主预写,此时会使用相同的优先级重启事务,但事务的候选人时间戳会被向前移动到这个新提交值的时间戳。
-
Writer encounters more recently read key: The read timestamp cache is consulted on each write at a node. If the write’s candidate timestamp is earlier than the low water mark on the cache itself (i.e. its last evicted timestamp) or if the key being written has a read timestamp later than the write’s candidate timestamp, this later timestamp value is returned with the write. A new timestamp forces a transaction restart only if it is serializable.
-
读事务遇到一个最近刚读的key : 一个节点上所有的写事务都会查询 read timestamp cache 。如果写事物的候选人时间戳比缓存中的低水位标记更早(如最近刚过期的时间戳),或者 如果正在写的key的读时间戳比候选人时间戳更晚,则写入一个具有更晚时间戳的值,这个新的更晚的时间戳会强制串行事务重启。
Transaction management
Transactions are managed by the client proxy (or gateway in SQL Azure parlance). Unlike in Spanner, writes are not buffered but are sent directly to all implicated ranges. This allows the transaction to abort quickly if it encounters a write conflict. The client proxy keeps track of all written keys in order to resolve write intents asynchronously upon transaction completion. If a transaction commits successfully, all intents are upgraded to committed. In the event a transaction is aborted, all written intents are deleted. The client proxy doesn’t guarantee it will resolve intents.
事务通过客户代理(类似微软SQL Azure的网关)进行管理,不像Spanner那样把写操作都缓存起来, cockroack会把写请求直接发送给所有关联的range. 这样当遇到定冲突时能够快速中止 事务。客户代理为了在事务完成时异步解析预写(write intent),会保存所有操作的key。当事务成功提交后,所有的预写都会被更新成已提交状态。如果事务被中止,所有的预写都将被删除。 客户代理不保证它会解析intent.
In the event the client proxy restarts before the pending transaction is committed, the dangling transaction would continue to live in the transaction table until aborted by another transaction. Transactions heartbeat the transaction table every five seconds by default. Transactions encountered by readers or writers with dangling intents which haven’t been heartbeat within the required interval are aborted. In the event the proxy restarts after a transaction commits but before the asynchronous resolution is complete, the dangling intents are upgraded when encountered by future readers and writers and the system does not depend on their timely resolution for correctness.
An exploration of retries with contention and abort times with abandoned transaction is here.
当pending状态的事务提交前,如果客户代理重启了,那么这些无主的事务将会继续留在事务表中,直到有其它事务中止它。事务与事务表默认每5s秒钟保持一次心跳。 当读操作或者写操作遇到无心跳的无主intent时会中止事务。 当事务已提交但尚未完成异步处理时,如果客户代理重启了,那么这些无主intent将被后来的读或者写操作更新。无主intent是否被及时处理并不影响系统正确性。
Transaction Table
Please see roachpb/data.proto for the up-to-date structures, the best entry point being message Transaction.
Pros
- No requirement for reliable code execution to prevent stalled 2PC protocol.
- Readers never block with SI semantics; with SSI semantics, they may abort.
- Lower latency than traditional 2PC commit protocol (w/o contention) because second phase requires only a single write to the transaction table instead of a synchronous round to all transaction participants.
- Priorities avoid starvation for arbitrarily long transactions and always pick a winner from between contending transactions (no mutual aborts).
- Writes not buffered at client; writes fail fast.
- No read-locking overhead required for serializable SI (in contrast to other SSI implementations).
-
Well-chosen (i.e. less random) priorities can flexibly give probabilistic guarantees on latency for arbitrary transactions (for example: make OLTP transactions 10x less likely to abort than low priority transactions, such as asynchronously scheduled jobs).
- 不依赖代码执行的可靠性来防止 2PC 协议陷入停滞
- SI语义事务读操作不会阻塞;SSI语议事务读操作会中止
- 比两阶段事务提交协议的时延更低。因为第二阶只需要写一次事务表。而不需要等待所有事务参数者。
- 以事务优先级来防止长事务的饥饿等待。总是从相争的事务中(且不能相互中止)选择优胜者。
- 写操作快速失败,在不客户端缓存
- 与其它SSI实现相比,cockroach的SSI没有read-locking开销
- 精心挑选的(即较少的随机)优先级可以灵活地保证任意事务的低时延(如:使用OLTP事务中止的可能性比异步调度任务这种低优先级事物小10倍)
Cons
- Reads from non-leader replicas still require a ping to the leader to update read timestamp cache.
- Abandoned transactions may block contending writers for up to the heartbeat interval, though average wait is likely to be considerably shorter (see graph in link). This is likely considerably more performant than detecting and restarting 2PC in order to release read and write locks.
- Behavior different than other SI implementations: no first writer wins, and shorter transactions do not always finish quickly. Element of surprise for OLTP systems may be a problematic factor.
-
Aborts can decrease throughput in a contended system compared with two phase locking. Aborts and retries increase read and write traffic, increase latency and decrease throughput.
- 从non-leader副本读取仍然需要ping leader以更新 read timestamp cache
- 在一个事务心跳区间(默认5s),已丢弃的事务有可能仍然阻塞相应的写操作.虽然平均的等待时间可能已相当小。这与检测并重启两阶段事物以释放读锁或者写锁相比,已经相当的高效了。
- 与其它SI实现行为不同:先提交的写并不一定先执行,短事务不一定总是先完成。这对一些OLTP系统来说,可能用问题。
- 对于有竞争的系统,与两阶段锁相比,中止事务可能降低系统吞吐量。因为中止和重启会增加读写的通信量,从而降低时延,减少系统吞吐能力。
Choosing a Timestamp
A key challenge of reading data in a distributed system with clock skew is choosing a timestamp guaranteed to be greater than the latest timestamp of any committed transaction (in absolute time). No system can claim consistency and fail to read already-committed data.
在一个存在时间漂移的分布式系统中,对于读操作来说,如何保证能选出一个比任何事务提交时间(指现实时间)都大的时间戳,是一个重要的挑战。 没有系统可以同时保证一致性,且不能读取已提交的数据。
Accomplishing consistency for transactions (or just single operations) accessing a single node is easy. The timestamp is assigned by the node itself, so it is guaranteed to be at a greater timestamp than all the existing timestamped data on the node.
在一个节点上实现事务(或者单一的操作)的一致性比较容易。因为数据时间戳是单节点自己产生的,不存在时种漂移,所以容易保证生成一个比所有已有数据时间戳都大的时间戳。
For multiple nodes, the timestamp of the node coordinating the
transaction t is used. In addition, a maximum timestamp t+ε is
supplied to provide an upper bound on timestamps for already-committed
data (ε is the maximum clock skew). As the transaction progresses, any
data read which have timestamps greater than t but less than t+ε
cause the transaction to abort and retry with the conflicting timestamp
tc, where tc > t. The maximum timestamp t+ε remains
the same. This implies that transaction restarts due to clock uncertainty
can only happen on a time interval of length ε.
在多节点上,一个节点上相应的事务时间戳t已被使用了,而且,对已提交的数据来说,t+ε 是节点所能提供的最大的时间戳的上限(ε 是最大时间漂移)。
当处理事务时,对任何时间戳大于t且小于t+ε的数据的读操作都会引起事务中止,并且以稍大的时间戳tc (tc > t)进行重试。
最大时间戳t+ε保持相同。这意味着,由于时钟的不确定性,事务只能以长度为ε的时间间隔进行重启。
We apply another optimization to reduce the restarts caused
by uncertainty. Upon restarting, the transaction not only takes
into account tc, but the timestamp of the node at the time
of the uncertain read tnode. The larger of those two timestamps
tc and tnode (likely equal to the latter) is used
to increase the read timestamp. Additionally, the conflicting node is
marked as “certain”. Then, for future reads to that node within the
transaction, we set MaxTimestamp = Read Timestamp, preventing further
uncertainty restarts.
我们使用另一种优化来减少这种不确定性引起的事务重启。当重启开始时,事务不仅要考虑tc , 也要考虑当产生 the uncertain read 时的节点时间 tnode .
tc 和 tnode (可能是后者)中更大的时间戳将被用来增加读时间戳。此外,冲突的节点被标记为 “certain” ,然后,这个节点上以后的的读事务将被设置MaxTimestamp = Read Timestamp,
来防止进一步不确定性造成重启。
Correctness follows from the fact that we know that at the time of the read, there exists no version of any key on that node with a higher timestamp than tnode. Upon a restart caused by the node, if the transaction encounters a key with a higher timestamp, it knows that in absolute time, the value was written after tnode was obtained, i.e. after the uncertain read. Hence the transaction can move forward reading an older version of the data (at the transaction’s timestamp). This limits the time uncertainty restarts attributed to a node to at most one. The tradeoff is that we might pick a timestamp larger than the optimal one (> highest conflicting timestamp), resulting in the possibility of a few more conflicts.
正确性来自以下事实:我们知道当读操作刚开始时,节点上没有任何key的版本有比tnode更大的时间戳。当节点的事务重启时,如果事务遇到一个具有更大时间戳的key时,
它就会知道,在现实时间上,这个值是在tnode时间之后被写的,比如是在the uncertain read之后的。因此,该事务可以向前移动读到一个旧版本的数据(位于该事务的时间戳)。
这将时间不确定的重启限定于最多一个节点。但却以选择一个比最优时间(> highest conflicting timestamp)更大的时间戳做为交换,这有可能造成更多的冲突。
We expect retries will be rare, but this assumption may need to be revisited if retries become problematic. Note that this problem does not apply to historical reads. An alternate approach which does not require retries makes a round to all node participants in advance and chooses the highest reported node wall time as the timestamp. However, knowing which nodes will be accessed in advance is difficult and potentially limiting. Cockroach could also potentially use a global clock (Google did this with Percolator), which would be feasible for smaller, geographically-proximate clusters.
我们预计重试将是罕见的,但如果重试会引入新的问题,我们可能需要重新审视这种假设。注意,这个问题不适用于读历史(historical reads)。 另一个不需求要重试的方法是:预先对所有参与的节点进行一次轮循,并选择所有节点中,最大的真实时间做为时间戳。然而,想预先知道哪个节点将被选中是很困难的,而且存在潜在的限制。 Cockroach 当然也可以,且可能使用全球时钟 (就像google那样 Percolator ). 使用那种规模小一点,地理上接近的全球时钟也是可行的.
Linearizability
线性化
First a word about Spanner.
By combining judicious use of wait intervals with accurate time signals,
Spanner provides a global ordering between any two non-overlapping transactions
(in absolute time) with ~14ms latencies. Put another way:
Spanner guarantees that if a transaction T1 commits (in absolute time)
before another transaction T2 starts, then T1’s assigned commit
timestamp is smaller than T2’s. Using atomic clocks and GPS receivers,
Spanner reduces their clock skew uncertainty to < 10ms (ε). To make
good on the promised guarantee, transactions must take at least double
the clock skew uncertainty interval to commit (2ε). See this
article
for a helpful overview of Spanner’s concurrency control.
先介绍一点Spanner的内容。通过结合精确的时间信号,使用合理的等待时间间隔,Spanner在任何两个非重叠的事务之间,以大约~14ms的时延,提供全球有序性。
换句话说:Spanner 确保如果一个事务T1在另一个事务T2开始之前提交了,则T1的时间戳一定比T2的时间戳小。通过使用原子钟和GPS信号,
Spanner将时钟漂移的减小到10ms (ε)以下。为此保证,事务必须有两倍的时钟漂移时间间隔(2ε)才能提交。想了解更多Spanner’的一致性控制,可以看这个 this article
Cockroach could make the same guarantees without specialized hardware, at the expense of longer wait times. If servers in the cluster were configured to work only with NTP, transaction wait times would likely to be in excess of 150ms. For wide-area zones, this would be somewhat mitigated by overlap from cross datacenter link latencies. If clocks were made more accurate, the minimal limit for commit latencies would improve.
Cockroach可以在没有特殊硬件的情况下得到和Spanner一样的承诺,只是要花费更长的等待时间。如果服务器集群只使用NTP进行时间同步,事务可能要等待超过150ms。 对于大面积的区域,这会随跨数据中心的链路延迟重叠而有所减轻。如果时钟更精确,提交延迟的最小限度也会减小。
然后,让我们退后一步,评估下Spanner的外部一致性保证是否值得自动提交等待。首先,如果完全忽略提交等待,系统仍然可以在任意时间产生一个一致的Map视图。 但因为存在时钟漂移,则可能先后提交两个时间上不重叠的事务,但在事实上先后顺序完全相反。换句话说,下面场景,对于一个客户端来说,在没有全局有序的保证下是完全有可能的。
- 开始事务T1 用来修改
x,提交时间是s1 - T1提交时,开启一个事务修改
y,提交时间是s2 - 同时读
x和y,发现s1 > s2 (!)
However, let’s take a step back and evaluate whether Spanner’s external consistency guarantee is worth the automatic commit wait. First, if the commit wait is omitted completely, the system still yields a consistent view of the map at an arbitrary timestamp. However with clock skew, it would become possible for commit timestamps on non-overlapping but causally related transactions to suffer temporal reverse. In other words, the following scenario is possible for a client without global ordering:
-
Start transaction T1 to modify value
xwith commit time s1 -
On commit of T1, start T2 to modify value
ywith commit time s2 -
Read
xandyand discover that s1 > s2 (!)
The external consistency which Spanner guarantees is referred to as linearizability. It goes beyond serializability by preserving information about the causality inherent in how external processes interacted with the database. The strength of Spanner’s guarantee can be formulated as follows: any two processes, with clock skew within expected bounds, may independently record their wall times for the completion of transaction T1 (T1end) and start of transaction T2 (T2start) respectively, and if later compared such that T1end < T2start, then commit timestamps s1 < s2. This guarantee is broad enough to completely cover all cases of explicit causality, in addition to covering any and all imaginable scenarios of implicit causality.
Spanner的外部一致性保证被称为线性化。它通过保存外部过程与数据库相互作用的因果关系信息超越了串行化。Spanner的承诺优点如下:任意两个过程,在预期范围内的时钟偏移下, 可以独立记录已完成事务T1 (T1end) 和刚开始的事务T2 (T2start)的真实时间。如果以后比较的结果是 T1end < T2start, 则可推出提交时间s1 < s2. 这个保证足以完全覆盖明确因果关系的所有情况,同时也可以覆盖所有能想出来的因果关系不明的情况。
Our contention is that causality is chiefly important from the perspective of a single client or a chain of successive clients (if a tree falls in the forest and nobody hears…). As such, Cockroach provides two mechanisms to provide linearizability for the vast majority of use cases without a mandatory transaction commit wait or an elaborate system to minimize clock skew.
我们的争论点是,因果关系是从一个单一的客户端的角度来看,还是从连续的客户链的角度来看,哪一种才是重要的 (如果一棵树倒在森林中,却没有人听到…)。 大多数使用场景是没有强制性的事务提交等待,或者没有一个为减小时钟漂移而精心设计的系统,Cockroach因此为这些场景提供了两种机制来提供线性化。
-
Clients provide the highest transaction commit timestamp with successive transactions. This allows node clocks from previous transactions to effectively participate in the formulation of the commit timestamp for the current transaction. This guarantees linearizability for transactions committed by this client.
Newly launched clients wait at least 2 * ε from process start time before beginning their first transaction. This preserves the same property even on client restart, and the wait will be mitigated by process initialization.
All causally-related events within Cockroach maintain linearizability.
-
客户端用连续的事务提供最大的事务提交时间戳。这使得节点可以根据之前事务的时间戳,快速的制定当前事务的提交时间戳。这保证了从此客户端上提交的事务的线性化。 新的客户端启动后在开启第一个事务之前,至少要等待2*ε的时间,即使客户端重新启动,也会保留相同的属性,并且等待将通过进程初始化来减轻。所有有因果关系的事件在Cockroach都保持线性化
-
已提交的事务会响应一个提交等待(commit wait)参数,该参数用来表示离额定的提交等待时间还有多久。此参数作为与事务协调者的达成的写共识(the consensus write)的一部份,这通常会比整个提交等待的时间短。 客户端在Cockroach事务之外执行的任何任务(如,往另一个分布式系统组件写数据)可以选择:在开始处理之前等剩余的
commit wait时间用完;或者选择将剩余的等待时间和提交时间戳 作为参数传给该任务,供其参考。这虽然将线性化交给了客户端来保证,但对于一个时钟漂移较大的系统来说,这却是一个减少事务提交时延的利器。当面临有反向通道依赖(backchannel dependencies)AugmentedTime 时 此功能可用于解决的排序问题。 -
Committed transactions respond with a commit wait parameter which represents the remaining time in the nominal commit wait. This will typically be less than the full commit wait as the consensus write at the coordinator accounts for a portion of it.
Clients taking any action outside of another Cockroach transaction (e.g. writing to another distributed system component) can either choose to wait the remaining interval before proceeding, or alternatively, pass the wait and/or commit timestamp to the execution of the outside action for its consideration. This pushes the burden of linearizability to clients, but is a useful tool in mitigating commit latencies if the clock skew is potentially large. This functionality can be used for ordering in the face of backchannel dependencies as mentioned in the AugmentedTime paper.
Using these mechanisms in place of commit wait, Cockroach’s guarantee can be formulated as follows: any process which signals the start of transaction T2 (T2start) after the completion of transaction T1 (T1end), will have commit timestamps such thats1 < s2.
在有提交等的地方使用这些机制。Cockroach可以保证:对任意处理过程,如果其中一个新开始的事务T2 (T2start) 晚于另一个已完成的事务T1 (T1end), 则其时间戳必然满足s1 < s2.
Logical Map Content
逻辑上,Map 在非系统数据的实际key:value对之前,会包含一系列的系统保留的key:value对,包括统计,range的元数据和节点统计.如:
Logically, the map contains a series of reserved system key / value pairs covering accounting, range metadata and node accounting before the actual key / value pairs for non-system data (e.g. the actual meat of the map).
\0\0meta1Range metadata for location of\0\0meta2.\0\0meta1<key1>Range metadata for location of\0\0meta2<key1>.- …
\0\0meta1<keyN>: Range metadata for location of\0\0meta2<keyN>.\0\0meta2: Range metadata for location of first non-range metadata key.\0\0meta2<key1>: Range metadata for location of<key1>.- …
\0\0meta2<keyN>: Range metadata for location of<keyN>.\0acct<key0>: Accounting for key prefix key0.- …
\0acct<keyN>: Accounting for key prefix keyN.\0node<node-address0>: Accounting data for node 0.- …
\0node<node-addressN>: Accounting data for node N.\0tree_root: Range key for root of range-spanning tree.\0tx<tx-id0>: Transaction record for transaction 0.- …
\0tx<tx-idN>: Transaction record for transaction N.\0zone<key0>: Zone information for key prefix key0.- …
\0zone<keyN>: Zone information for key prefix keyN.<>acctd<metric0>: Accounting data for Metric 0 for empty key prefix.- …
<>acctd<metricN>: Accounting data for Metric N for empty key prefix.<key0>:<value0>The first user data key.**- …
<keyN>:<valueN>The last user data key.**
There are some additional system entries sprinkled amongst the non-system keys. See the Key-Prefix Accounting section in this document for further details.
还有一些附加在非系统keys之间的系统条目. 进一步了解细节,可以参考Key-Prefix Accounting章节。
Node Storage
Nodes maintain a separate instance of RocksDB for each disk. Each RocksDB instance hosts any number of ranges. RPCs arriving at a RoachNode are multiplexed based on the disk name to the appropriate RocksDB instance. A single instance per disk is used to avoid contention. If every range maintained its own RocksDB, global management of available cache memory would be impossible and writers for each range would compete for non-contiguous writes to multiple RocksDB logs.
In addition to the key/value pairs of the range itself, various range metadata is maintained.
-
range-spanning tree node links
-
participating replicas
-
consensus metadata
-
split/merge activity
A really good reference on tuning Linux installations with RocksDB is here.
Cockroach节点为每一块磁盘维护一个单独的RocksDB实例。每个RocksDB实例保存有若干个ranges。到达一个RoachNode节点上的RPCs会被复用到适当RocksDB实例。 每个磁盘一个实例可以防止竞争。如果每个range都维持一个RocksDB,就不可能管理一个全局可用的缓存,且每个range的写操作将竞争非连续写入多个RocksDB日志。
除了range自已的key:value 对,也保存了各种range的元数据。
-
range-spanning tree node links
-
participating replicas
-
consensus metadata
-
split/merge activity
Range Metadata
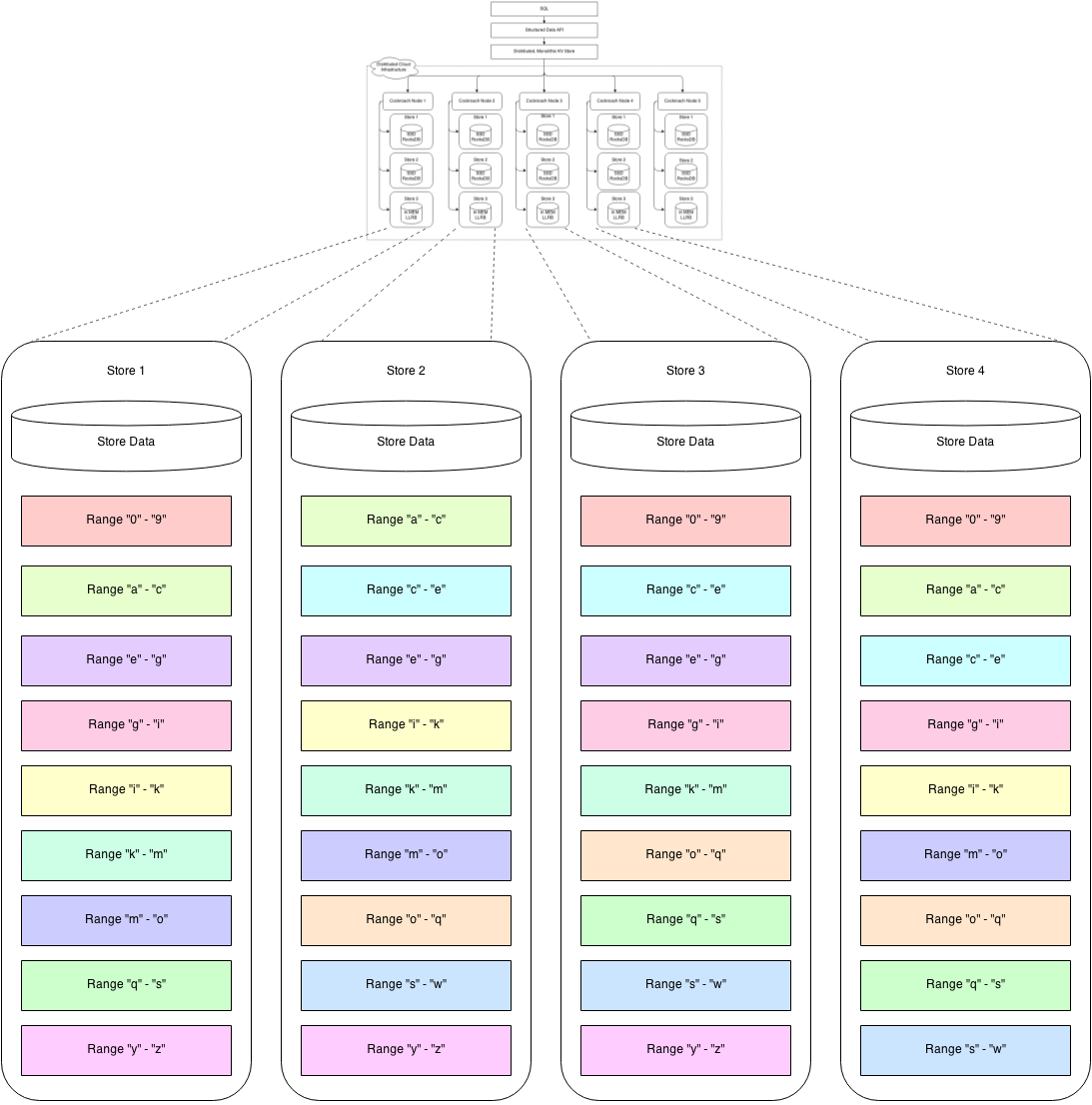
The default approximate size of a range is 64M (2\^26 B). In order to support 1P (2\^50 B) of logical data, metadata is needed for roughly 2\^(50 - 26) = 2\^24 ranges. A reasonable upper bound on range metadata size is roughly 256 bytes (3*12 bytes for the triplicated node locations and 220 bytes for the range key itself*). 2\^24 ranges * 2\^8 B would require roughly 4G (2\^32 B) to store–too much to duplicate between machines. Our conclusion is that range metadata must be distributed for large installations.
一个range默认是64M (2\^26 B), 要支持1PB(2\^50 B)的数据大概需要2\^(50 - 26) = 2\^24 = 16M个range。一个元数据最大256字节是比较合理的(其中3*12字节用来保存3个节点的位置,余下220字节保存此range自已的key)。 2\^24 = 16M 个range,每个256字节大概就需要4G (2\^32 B)字节,这太大了而不能在主机间进行复制。我们的结论是,对于很大的集群,range的元数据必须是分布式的。
To keep key lookups relatively fast in the presence of distributed metadata, we store all the top-level metadata in a single range (the first range). These top-level metadata keys are known as meta1 keys, and are prefixed such that they sort to the beginning of the key space. Given the metadata size of 256 bytes given above, a single 64M range would support 64M/256B = 2\^18 ranges, which gives a total storage of 64M * 2\^18 = 16T. To support the 1P quoted above, we need two levels of indirection, where the first level addresses the second, and the second addresses user data. With two levels of indirection, we can address 2\^(18 + 18) = 2\^36 ranges; each range addresses 2\^26 B, and altogether we address 2\^(36+26) B = 2\^62 B = 4E of user data.
因为元数据是分布式保存的,为了保证key的查找效率,我们把所有顶层的元数据保存在一个range里(第一个range). 这些顶层的元数据的key是 meta1 ,用这样的前缀让它们排在key空间的前边。 前边说过了一个元数据是256字节,一个64M的range可以保存 2\^18 = 256K个range的元数据,总共可以提供64M * 2\^18 =16T的存储空间。为了提供1P的存储空间,我们需要两级寻址(两级索引 ,第一级用来保存第二级的地址,第二级用来保存数据)。 采用两级寻址,我们就可以支持2\^(18 + 18) = 64G个range, 每个range支持寻址2\^26 B = 64M ,则总共可寻址2\^(36+26) B = 2\^62 B = 4E 的数据空间.
For a given user-addressable key1, the associated meta1 record is found
at the successor key to key1 in the meta1 space. Since the meta1 space
is sparse, the successor key is defined as the next key which is present. The
meta1 record identifies the range containing the meta2 record, which is
found using the same process. The meta2 record identifies the range
containing key1, which is again found the same way (see examples below).
对于一个用户给定的key1 ,其对应的 meta1 记录位于第一个range(rang0)上一个叫做 successor key 的key上,因为meta1的空间是稀疏的,successor key就成为了下一个已存在的key. meta1 记录了meta2 记录所在的range.
meta2 record 则记录了key1所在的range.
Concretely, metadata keys are prefixed by \0\0meta{1,2}; the two null
characters provide for the desired sorting behaviour. Thus, key1’s
meta1 record will reside at the successor key to \0\0\meta1<key1>.
具体上是:key的元数据以 \0\0meta{1,2} 为前缀。 以两个\0\0开头是为了满足我们的排序要求。key1的元数据 meta1 会被保存在 \0\0\meta1<key1> 这个key上,即上面说的successor key.
Note: we append the end key of each range to meta{1,2} records because the RocksDB iterator only supports a Seek() interface which acts as a Ceil(). Using the start key of the range would cause Seek() to find the key after the meta indexing record we’re looking for, which would result in having to back the iterator up, an option which is both less efficient and not available in all cases.
注意: 我们在元数据记录上追加保存每个range的最后一个key , 是因为 RocksDB的迭代器只提供一个Seek()接口,功能类似Ceil() (上向取整)。 如果保存range的第一个key, 当使用seek()查询元数据上的key时,…, 不方便,且效率不高。
下面展示一个有三个range的元数据索引结构。省略号表示跟后边的key/value对一样。只有切分range时需要更新range的元数据,需要知道元数据的分布信息,其它情况都不用管它。
The following example shows the directory structure for a map with three ranges worth of data. Ellipses indicate additional key/value pairs to fill an entire range of data. Except for the fact that splitting ranges requires updates to the range metadata with knowledge of the metadata layout, the range metadata itself requires no special treatment or bootstrapping.
Range 0 (located on servers dcrama1:8000, dcrama2:8000,
dcrama3:8000)
\0\0meta1\xff:dcrama1:8000,dcrama2:8000,dcrama3:8000\0\0meta2<lastkey0>:dcrama1:8000,dcrama2:8000,dcrama3:8000\0\0meta2<lastkey1>:dcrama4:8000,dcrama5:8000,dcrama6:8000\0\0meta2\xff:dcrama7:8000,dcrama8:8000,dcrama9:8000- …
<lastkey0>:<lastvalue0>
Range 1 (located on servers dcrama4:8000, dcrama5:8000,
dcrama6:8000)
- …
<lastkey1>:<lastvalue1>
Range 2 (located on servers dcrama7:8000, dcrama8:8000,
dcrama9:8000)
- …
<lastkey2>:<lastvalue2>
如果一个range很小,不足一个range上限,所有的元数据都会位于相同的range里。
Consider a simpler example of a map containing less than a single range of data. In this case, all range metadata and all data are located in the same range:
Range 0 (located on servers dcrama1:8000, dcrama2:8000,
dcrama3:8000)*
\0\0meta1\xff:dcrama1:8000,dcrama2:8000,dcrama3:8000\0\0meta2\xff:dcrama1:8000,dcrama2:8000,dcrama3:8000<key0>:<value0>...
最终,如果数据足够大,两层索引看起来像这个( 这里没有写range副本,只简单写了range的编号) :
Finally, a map large enough to need both levels of indirection would look like (note that instead of showing range replicas, this example is simplified to just show range indexes):
Range 0
\0\0meta1<lastkeyN-1>: Range 0\0\0meta1\xff: Range 1\0\0meta2<lastkey1>: Range 1\0\0meta2<lastkey2>: Range 2\0\0meta2<lastkey3>: Range 3- …
\0\0meta2<lastkeyN-1>: Range 262143
Range 1
\0\0meta2<lastkeyN>: Range 262144\0\0meta2<lastkeyN+1>: Range 262145- …
\0\0meta2\xff: Range 500,000- …
<lastkey1>:<lastvalue1>
Range 2
- …
<lastkey2>:<lastvalue2>
Range 3
- …
<lastkey3>:<lastvalue3>
Range 262144
- …
<lastkeyN>:<lastvalueN>
Range 262145
- …
<lastkeyN+1>:<lastvalueN+1>
上面range 262144 近似值。一个元数据range 真正可寻址的范围依赖于key的大小。如果key的size足够小,可寻址范围会增加,反之亦然。
通过上面的例子,寻址一个key最多需要3次read,就可获取<key>对应的value.
Note that the choice of range 262144 is just an approximation. The
actual number of ranges addressable via a single metadata range is
dependent on the size of the keys. If efforts are made to keep key sizes
small, the total number of addressable ranges would increase and vice
versa.
From the examples above it’s clear that key location lookups require at
most three reads to get the value for <key>:
- lower bound of
\0\0meta1<key> - lower bound of
\0\0meta2<key>, <key>.
对于很小的map, 可以在Range 0上一次RPC调用内完成所有查询。 16T以下的Map需要2次。客户端缓存整个range元数据, 我们希望客户端的数据局部性越高越好。客户端可能 有过期的条目。 在一次查询中,如果range没有达到客户端的期望,客户端就会删除该过期条目,并发起一个新的查询.
For small maps, the entire lookup is satisfied in a single RPC to Range 0. Maps containing less than 16T of data would require two lookups. Clients cache both levels of range metadata, and we expect that data locality for individual clients will be high. Clients may end up with stale cache entries. If on a lookup, the range consulted does not match the client’s expectations, the client evicts the stale entries and possibly does a new lookup.
Raft - Consistency of Range Replicas
Raft - range副本的一致性
Each range is configured to consist of three or more replicas, as specified by their ZoneConfig. The replicas in a range maintain their own instance of a distributed consensus algorithm. We use the Raft consensus algorithm as it is simpler to reason about and includes a reference implementation covering important details. ePaxos has promising performance characteristics for WAN-distributed replicas, but it does not guarantee a consistent ordering between replicas.
根据ZoneConfig的配置,每个range都会包含3个或者更多的副本。 一个range里的副本会维护自己的分布式一致性算法实例。我们使用 Raft, 因为它足够简单,并且有一个包含重要的细节的参考实现。ePaxos
Raft elects a relatively long-lived leader which must be involved to propose commands. It heartbeats followers periodically and keeps their logs replicated. In the absence of heartbeats, followers become candidates after randomized election timeouts and proceed to hold new leader elections. Cockroach weights random timeouts such that the replicas with shorter round trip times to peers are more likely to hold elections first (not implemented yet). Only the Raft leader may propose commands; followers will simply relay commands to the last known leader.
Raft 选举一个相对长寿的leader来提交指令 ,leader会与follower会保持周期性心跳,并让follower保存log的副本. 如果心跳消失,在经过随机的election timeouts时间,follower成为候选人(candidates) , 并且继续发起新的leader选举过程。Cockroach使用随机时间,这样通信往返时间短的会更易第一个发起选举。只有leader才能提交指令,followers只简单地传递命令到最后一个已知的领导者。
Our Raft implementation was developed together with CoreOS, but adds an extra layer of optimization to account for the fact that a single Node may have millions of consensus groups (one for each Range). Areas of optimization are chiefly coalesced heartbeats (so that the number of nodes dictates the number of heartbeats as opposed to the much larger number of ranges) and batch processing of requests. Future optimizations may include two-phase elections and quiescent ranges (i.e. stopping traffic completely for inactive ranges).
Cockroach的Raft实现在CoreOS的基础上,增加额外的优化层,因为考虑到一个节点可能有几百万的一致性组(每个range一个)。少部分优化主要是合并心跳(与数量巨大的range相反,节点数量决定了心跳的数量)和 请求批处理。将来的优化还包括二阶段选举和静态range.
Range Leadership (Leader Leases)
As outlined in the Raft section, the replicas of a Range are organized as a Raft group and execute commands from their shared commit log. Going through Raft is an expensive operation though, and there are tasks which should only be carried out by a single replica at a time (as opposed to all of them).
For these reasons, Cockroach introduces the concept of Range Leadership: This is a lease held for a slice of (database, i.e. hybrid logical) time and is established by committing a special log entry through Raft containing the interval the leadership is going to be active on, along with the Node:RaftID combination that uniquely describes the requesting replica. Reads and writes must generally be addressed to the replica holding the lease; if none does, any replica may be addressed, causing it to try to obtain the lease synchronously. Requests received by a non-leader (for the HLC timestamp specified in the request’s header) fail with an error pointing at the replica’s last known leader. These requests are retried transparently with the updated leader by the gateway node and never reach the client.
像上面Raft概述里说的,一个range的副本作为一个Raft组来执行共享commit log 里的指令. 通过Raft实现一致性是一个昂贵的操作,且有些任务同一时刻只能在一个副本里进行处理。因此, Cockroach将介绍一些Range Leadership概念: 这是一个时间片的租约,通过Raft算法提交的一个特殊的log 条目建立的,包含了leadership活跃的时间间隔,和Node:RaftID的组合,该组合 用来表示唯一一个正在请求的副本。读请求和写请求必须寻址到撑握此租约的副本上。如果无法寻址到,就可能寻址到任意的副本上,获取请求的副本将尝试同步获取此租约。 由non-leader接收的请求失败后,将抛出一个指向副本最后一个leader的错误信息。这些请求将通过网关节点透明的发给新leader进行重试,客户端毫无感知。
持有租约的副本将处理一些特殊range的维护任务,如:
- 通报第一个range的信息
- 拆分,合并,平衡range
并且,非常重要的,可以满足本地读取,而不引起Raft的开销.
如果通过Raft读取时,持有租约的副本还要确定它缓存的时间戳必须大于上一个有持有租约的副本(因为这样才能兼容发生在上一个leader上的读操作)。 这是通过把timestamp cache的低水位标记设置成先前租约期满加上最大时钟漂移完成的。
The replica holding the lease is in charge or involved in handling Range-specific maintenance tasks such as
- gossiping the sentinel and/or first range information
- splitting, merging and rebalancing
and, very importantly, may satisfy reads locally, without incurring the overhead of going through Raft.
Since reads bypass Raft, a new lease holder will, among other things, ascertain that its timestamp cache does not report timestamps smaller than the previous lease holder’s (so that it’s compatible with reads which may have occurred on the former leader). This is accomplished by setting the low water mark of the timestamp cache to the expiration of the previous lease plus the maximum clock offset.
Relationship to Raft leadership
Range leadership is completely separate from Raft leadership, and so without further efforts, Raft and Range leadership may not be represented by the same replica most of the time. This is convenient semantically since it decouples these two types of leadership and allows the use of Raft as a “black box”, but for reasons of performance, it is desirable to have both on the same replica. Otherwise, sending a command through Raft always incurs the overhead of being proposed to the Range leader’s Raft instance first, which must relay it to the Raft leader, which finally commits it into the log and updates its followers, including the Range leader. This yields correct results but wastes several round-trip delays, and so we will make sure that in the vast majority of cases Range and Raft leadership coincide. A fairly easy method for achieving this is to have each new lease period (extension or new) be accompanied by a stipulation to the lease holder’s replica to start Raft elections (unless it’s already leading), though some care should be taken that Range leadership is relatively stable and long-lived to avoid a large number of Raft leadership transitions.
Range Leader和Raft Leader是完全独立的,没有进一步的努力,Raft 和 Range的Leader将不大可能位于同一个副本。这很实用,因为语义上它分离这两种类型的领导,并允许使Raft作为一个“黑匣子”来使用。 但因为性能的原因,让一个副本同时具有两种角色最好,否则通过Raft发送一个指令时,总是先提交给range leader,range leader再转发给raft leader , raft leader再进行提交并更新也包括range leader在内的其它follower range,,从而带来开销, 这虽然能产生正确的结果,但却会浪费几轮交互时间,所以得保证绝大多数情况,Raft 和 Range的leader都是一个副本。实现这一目标的一个相当简单的方法是: 规定每一次延长或开始新的租约期限时,必须由租约持有者来发起raft选举(除非它是已经leader),还要注意要保证Range leader稳定且长期存活,来避免大量Raft leader转换。
Command Execution Flow
This subsection describes how a leader replica processes a read/write command in more details. Each command specifies (1) a key (or a range of keys) that the command accesses and (2) the ID of a range which the key(s) belongs to. When receiving a command, a RoachNode looks up a range by the specified Range ID and checks if the range is still responsible for the supplied keys. If any of the keys do not belong to the range, the RoachNode returns an error so that the client will retry and send a request to a correct range.
这一章节详细介绍leader 副本是如何处理读写命令的。每一个命令都指明一个要处理的key(或者一个key的范围)和包含该key的range的ID. 当RoachNode收到一个命令时会根据rangID获取对应的range,并且检查 这个range是否包含相应的keys. 如果不包含,RoachNode返回error,客户端收到error后继续重试直到找到正确的range.
When all the keys belong to the range, the RoachNode attempts to process the command. If the command is an inconsistent read-only command, it is processed immediately. If the command is a consistent read or a write, the command is executed when both of the following conditions hold:
- The range replica has a leader lease.
- There are no other running commands whose keys overlap with the submitted command and cause read/write conflict.
当命令中的所有keys都包含在range中,RoachNode就开始执行命令。如果命令是一个非一致性的只读命令,会立即处理。如果是要求一致性的读写命令,只要满足以下两个条件,命令才被执行:
- 该range必须是leader
- 当前要读写的keys与正在处理的命令的keys不能有重叠。
When the first condition is not met, the replica attempts to acquire a lease or returns an error so that the client will redirect the command to the current leader. The second condition guarantees that consistent read/write commands for a given key are sequentially executed.
如果第一个条件不满足,副本尝试获取leader 租约(leader lease),如未获取租约则给客户端返回error,客户端将命令发送给当前的leader.第二个条件保证对一个key的一致性读写命令被串行执行。
如果两个条件都满足了,就开始处理命令。对于一致性的读命令,会立即在此节点上执行。一致性写命令会被提交到raft log里以便让每个副本都能执行这个命令。所有的命令都会产生确定的结果,所以 range 的所有副本能保证一致性。
When the above two conditions are met, the leader replica processes the command. Consistent reads are processed on the leader immediately. Write commands are committed into the Raft log so that every replica will execute the same commands. All commands produce deterministic results so that the range replicas keep consistent states among them.
当写命令执行完成,所有的副本更新他们的响应缓存以保证幂等性。当写命令执行完成,leader更新它的时间戳缓存以保存对此key的最新读时间。
When a write command completes, all the replica updates their response cache to ensure idempotency. When a read command completes, the leader replica updates its timestamp cache to keep track of the latest read for a given key.
当命令正在执行时,有可能leader租约期了。在执行命令之前,每个副本都要检查是否仍然持有租约。 如果租约到期了,命令会被拒绝。 There is a chance that a leader lease gets expired while a command is executed. Before executing a command, each replica checks if a replica proposing the command has a still lease. When the lease has been expired, the command will be rejected by the replica.
Splitting / Merging Ranges
RoachNodes 根据他们是否超过容量或负荷的最大或最小阈值来决定拆分或者合并range. 容量或负荷如果任意一个超过最大值就会拆分;如果都小于最小值则会合并。
RoachNodes split or merge ranges based on whether they exceed maximum or minimum thresholds for capacity or load. Ranges exceeding maximums for either capacity or load are split; ranges below minimums for both capacity and load are merged.
ranges 保存与key前缀相同的统计信息。形成一个具有分钟级粒度的数据点的时间序列。从字节数到读/写队列大小的所有信息。 对这些统计信息进行分析可以做为拆分合并的依据。range 的大小和IOps这两个敏感指标被用来拆分合并。总的读写队列等待时间这个指标作为节点需要rebalance的依据。 这些指标通过Gossip算法在每个range间传递。
Ranges maintain the same accounting statistics as accounting key prefixes. These boil down to a time series of data points with minute granularity. Everything from number of bytes to read/write queue sizes. Arbitrary distillations of the accounting stats can be determined as the basis for splitting / merging. Two sensible metrics for use with split/merge are range size in bytes and IOps. A good metric for rebalancing a replica from one node to another would be total read/write queue wait times. These metrics are gossipped, with each range / node passing along relevant metrics if they’re in the bottom or top of the range it’s aware of.
range发现自己超过了阈值就拆分,为此,range leader会计算一个适当的候选key并通过raft协议进行拆分。与拆分对比,合并则需要range的容量和负载都必须小于阈值。 被合并的range会从此range之前和之后的range中选择一个较小的进行合并。
A range finding itself exceeding either capacity or load threshold splits. To this end, the range leader computes an appropriate split key candidate and issues the split through Raft. In contrast to splitting, merging requires a range to be below the minimum threshold for both capacity and load. A range being merged chooses the smaller of the ranges immediately preceding and succeeding it.
range拆分,合并,平衡range 和恢复时,在节点间移动数据都遵循相同的基础算法。创建新的目标副本并添加到源range的副本集中,然后新的副本通过重放所有日志进行更新,或者通过copy一个源副本 数据的快照并且重放快照日间以后的日志进行更新。一旦一个新副本已更新到最新状态,range元数据也更新完成,老的源副本就可能被删除。
Splitting, merging, rebalancing and recovering all follow the same basic algorithm for moving data between roach nodes. New target replicas are created and added to the replica set of source range. Then each new replica is brought up to date by either replaying the log in full or copying a snapshot of the source replica data and then replaying the log from the timestamp of the snapshot to catch up fully. Once the new replicas are fully up to date, the range metadata is updated and old, source replica(s) deleted if applicable.
Coordinator (leader replica)
if splitting
SplitRange(split_key): splits happen locally on range replicas and
only after being completed locally, are moved to new target replicas.
else if merging
Choose new replicas on same servers as target range replicas;
add to replica set.
else if rebalancing || recovering
Choose new replica(s) on least loaded servers; add to replica set.
New Replica
Bring replica up to date:
if all info can be read from replicated log
copy replicated log
else
snapshot source replica
send successive ReadRange requests to source replica
referencing snapshot
if merging
combine ranges on all replicas
else if rebalancing || recovering
remove old range replica(s)
RoachNodes split ranges when the total data in a range exceeds a configurable maximum threshold. Similarly, ranges are merged when the total data falls below a configurable minimum threshold.
TBD: flesh this out: Especially for merges (but also rebalancing) we have a range disappearing from the local node; that range needs to disappear gracefully, with a smooth handoff of operation to the new owner of its data.
节点通过负载统计信息检查到其负载或容量是集群中最坏的一个,range会进行rebalanc,并且在同一个数据中心选择备用节点。 Ranges are rebalanced if a node determines its load or capacity is one of the worst in the cluster based on gossipped load stats. A node with spare capacity is chosen in the same datacenter and a special-case split is done which simply duplicates the data 1:1 and resets the range configuration metadata.
Range-Spanning Binary Tree
A crucial enhancement to the organization of range metadata is to
augment the bi-level range metadata lookup with a minimum spanning tree,
implemented as a left-leaning red-black tree over all ranges in the map.
This tree structure allows the system to start at any key prefix and
efficiently traverse an arbitrary key range with minimal RPC traffic,
minimal fan-in and fan-out, and with bounded time complexity equal to
2*log N steps, where N is the total number of ranges in the system.
Unlike the range metadata rows prefixed with \0\0meta[1|2], the
metadata for the range-spanning tree (e.g. parent range and left / right
child ranges) is stored directly at the ranges as non-map metadata. The
metadata for each node of the tree (e.g. links to parent range, left
child range, and right child range) is stored with the range metadata.
In effect, the tree metadata is stored implicitly. In order to traverse
the tree, for example, you’d need to query each range in turn for its
metadata.
Any time a range is split or merged, both the bi-level range lookup metadata and the per-range binary tree metadata are updated as part of the same distributed transaction. The total number of nodes involved in the update is bounded by 2 + log N (i.e. 2 updates for meta1 and meta2, and up to log N updates to balance the range-spanning tree). The range corresponding to the root node of the tree is stored in \0tree_root.
As an example, consider the following set of nine ranges and their associated range-spanning tree:
R0: aa - cc, R1: *cc - lll, R2: *lll - llr, R3: *llr - nn, R4: *nn - rr, R5: *rr - ssss, R6: *ssss - sst, R7: *sst - vvv, R8: *vvv - zzzz.
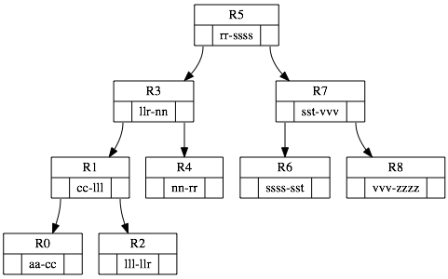
The range-spanning tree has many beneficial uses in Cockroach. It provides a ready made solution to scheduling mappers and sorting / reducing during map-reduce operations. It also provides a mechanism for visiting every Raft replica range which comprises a logical key range. This is used to periodically find the oldest extant write intent over the entire system.
The range-spanning tree provides a convenient mechanism for planning and executing parallel queries. These provide the basis for Dremel-like query execution trees and it’s easy to imagine supporting a subset of SQL or even javascript-based user functions for complex data analysis tasks.
Node Allocation (via Gossip)
通过Gossip算法,分配新节点
当rang拆分的时候必须要分配新的节点。cockroach使用gossip算法将新增节点状态信息通知到其它所有节点。
New nodes must be allocated when a range is split. Instead of requiring every RoachNode to know about the status of all or even a large number of peer nodes –or– alternatively requiring a specialized curator or master with sufficiently global knowledge, we use a gossip protocol to efficiently communicate only interesting information between all of the nodes in the cluster. What’s interesting information? One example would be whether a particular node has a lot of spare capacity. Each node, when gossiping, compares each topic of gossip to its own state. If its own state is somehow “more interesting” than the least interesting item in the topic it’s seen recently, it includes its own state as part of the next gossip session with a peer node. In this way, a node with capacity sufficiently in excess of the mean quickly becomes discovered by the entire cluster. To avoid piling onto outliers, nodes from the high capacity set are selected at random for allocation.
The gossip protocol itself contains two primary components:
-
Peer Selection: each node maintains up to N peers with which it regularly communicates. It selects peers with an eye towards maximizing fanout. A peer node which itself communicates with an array of otherwise unknown nodes will be selected over one which communicates with a set containing significant overlap. Each time gossip is initiated, each nodes’ set of peers is exchanged. Each node is then free to incorporate the other’s peers as it sees fit. To avoid any node suffering from excess incoming requests, a node may refuse to answer a gossip exchange. Each node is biased towards answering requests from nodes without significant overlap and refusing requests otherwise.
Peers are efficiently selected using a heuristic as described in Agarwal & Trachtenberg (2006).
TBD: how to avoid partitions? Need to work out a simulation of the protocol to tune the behavior and see empirically how well it works.
-
Gossip Selection: what to communicate. Gossip is divided into topics. Load characteristics (capacity per disk, cpu load, and state [e.g. draining, ok, failure]) are used to drive node allocation. Range statistics (range read/write load, missing replicas, unavailable ranges) and network topology (inter-rack bandwidth/latency, inter-datacenter bandwidth/latency, subnet outages) are used for determining when to split ranges, when to recover replicas vs. wait for network connectivity, and for debugging / sysops. In all cases, a set of minimums and a set of maximums is propagated; each node applies its own view of the world to augment the values. Each minimum and maximum value is tagged with the reporting node and other accompanying contextual information. Each topic of gossip has its own protobuf to hold the structured data. The number of items of gossip in each topic is limited by a configurable bound.
For efficiency, nodes assign each new item of gossip a sequence number and keep track of the highest sequence number each peer node has seen. Each round of gossip communicates only the delta containing new items.
Node Accounting
节点信息统计
The gossip protocol discussed in the previous section is useful to
quickly communicate fragments of important information in a
decentralized manner. However, complete accounting for each node is also
stored to a central location, available to any dashboard process. This
is done using the map itself. Each node periodically writes its state to
the map with keys prefixed by \0node, similar to the first level of
range metadata, but with an ‘node’ suffix. Each value is a protobuf
containing the full complement of node statistics–everything
communicated normally via the gossip protocol plus other useful, but
non-critical data.
The range containing the first key in the node accounting table is
responsible for gossiping the total count of nodes. This total count is
used by the gossip network to most efficiently organize itself. In
particular, the maximum number of hops for gossipped information to take
before reaching a node is given by ceil(log(node count) / log(max
fanout)) + 1.
Key-prefix Accounting and Zones
Arbitrarily fine-grained accounting is specified via key prefixes. Key prefixes can overlap, as is necessary for capturing hierarchical relationships. For illustrative purposes, let’s say keys specifying rows in a set of databases have the following format:
<db>:<table>:<primary-key>[:<secondary-key>]
In this case, we might collect accounting with key prefixes:
db1, db1:user, db1:order,
Accounting is kept for the entire map by default.
Accounting
to keep accounting for a range defined by a key prefix, an entry is created in the accounting system table. The format of accounting table keys is:
\0acct<key-prefix>
In practice, we assume each RoachNode capable of caching the entire accounting table as it is likely to be relatively small.
Accounting is kept for key prefix ranges with eventual consistency for efficiency. There are two types of values which comprise accounting: counts and occurrences, for lack of better terms. Counts describe system state, such as the total number of bytes, rows, etc. Occurrences include transient performance and load metrics. Both types of accounting are captured as time series with minute granularity. The length of time accounting metrics are kept is configurable. Below are examples of each type of accounting value.
System State Counters/Performance
- Count of items (e.g. rows)
- Total bytes
- Total key bytes
- Total value length
- Queued message count
- Queued message total bytes
- Count of values < 16B
- Count of values < 64B
- Count of values < 256B
- Count of values < 1K
- Count of values < 4K
- Count of values < 16K
- Count of values < 64K
- Count of values < 256K
- Count of values < 1M
- Count of values > 1M
- Total bytes of accounting
Load Occurrences
- Get op count
- Get total MB
- Put op count
- Put total MB
- Delete op count
- Delete total MB
- Delete range op count
- Delete range total MB
- Scan op count
- Scan op MB
- Split count
- Merge count
Because accounting information is kept as time series and over many possible metrics of interest, the data can become numerous. Accounting data are stored in the map near the key prefix described, in order to distribute load (for both aggregation and storage).
Accounting keys for system state have the form:
<key-prefix>|acctd<metric-name>*. Notice the leading ‘pipe’
character. It’s meant to sort the root level account AFTER any other
system tables. They must increment the same underlying values as they
are permanent counts, and not transient activity. Logic at the
RoachNode takes care of snapshotting the value into an appropriately
suffixed (e.g. with timestamp hour) multi-value time series entry.
Keys for perf/load metrics:
<key-prefix>acctd<metric-name><hourly-timestamp>.
<hourly-timestamp>-suffixed accounting entries are multi-valued,
containing a varint64 entry for each minute with activity during the
specified hour.
To efficiently keep accounting over large key ranges, the task of
aggregation must be distributed. If activity occurs within the same
range as the key prefix for accounting, the updates are made as part
of the consensus write. If the ranges differ, then a message is sent
to the parent range to increment the accounting. If upon receiving the
message, the parent range also does not include the key prefix, it in
turn forwards it to its parent or left child in the balanced binary
tree which is maintained to describe the range hierarchy. This limits
the number of messages before an update is visible at the root to 2*log N,
where N is the number of ranges in the key prefix.
Zones
zones are stored in the map with keys prefixed by
\0zone followed by the key prefix to which the zone
configuration applies. Zone values specify a protobuf containing
the datacenters from which replicas for ranges which fall under
the zone must be chosen.
Please see config/config.proto for up-to-date data structures used, the best entry point being message ZoneConfig.
If zones are modified in situ, each RoachNode verifies the existing zones for its ranges against the zone configuration. If it discovers differences, it reconfigures ranges in the same way that it rebalances away from busy nodes, via special-case 1:1 split to a duplicate range comprising the new configuration.
Key-Value API
see the protobufs in roachpb/, in particular roachpb/api.proto and the comments within.
Structured Data API
A preliminary design can be found in the Go source documentation.
Appendix
Datastore Goal Articulation
There are other important axes involved in data-stores which are less well understood and/or explained. There is lots of cross-dependency, but it’s safe to segregate two more of them as (a) scan efficiency, and (b) read vs write optimization.
Datastore Scan Efficiency Spectrum
Scan efficiency refers to the number of IO ops required to scan a set of sorted adjacent rows matching a criteria. However, it’s a complicated topic, because of the options (or lack of options) for controlling physical order in different systems.
- Some designs either default to or only support “heap organized” physical records (Oracle, MySQL, Postgres, SQLite, MongoDB). In this design, a naive sorted-scan of an index involves one IO op per record.
- In these systems it’s possible to “fully cover” a sorted-query in an index with some write-amplification.
- In some systems it’s possible to put the primary record data in a sorted btree instead of a heap-table (default in MySQL/Innodb, option in Oracle).
- Sorted-order LSM NoSQL could be considered index-organized-tables, with efficient scans by the row-key. (HBase).
- Some NoSQL is not optimized for sorted-order retrieval, because of hash-bucketing, primarily based on the Dynamo design. (Cassandra, Riak)

Read vs. Write Optimization Spectrum
Read vs write optimization is a product of the underlying sorted-order data-structure used. Btrees are read-optimized. Hybrid write-deferred trees are a balance of read-and-write optimizations (shuttle-trees, fractal-trees, stratified-trees). LSM separates write-incorporation into a separate step, offering a tunable amount of read-to-write optimization. An “ideal” LSM at 0%-write-incorporation is a log, and at 100%-write-incorporation is a btree.
The topic of LSM is confused by the fact that LSM is not an algorithm, but a design pattern, and usage of LSM is hindered by the lack of a de-facto optimal LSM design. LevelDB/RocksDB is one of the more practical LSM implementations, but it is far from optimal. Popular text-indicies like Lucene are non-general purpose instances of write-optimized LSM.
Further, there is a dependency between access pattern (read-modify-write vs blind-write and write-fraction), cache-hitrate, and ideal sorted-order algorithm selection. At a certain write-fraction and read-cache-hitrate, systems achieve higher total throughput with write-optimized designs, at the cost of increased worst-case read latency. As either write-fraction or read-cache-hitrate approaches 1.0, write-optimized designs provide dramatically better sustained system throughput when record-sizes are small relative to IO sizes.
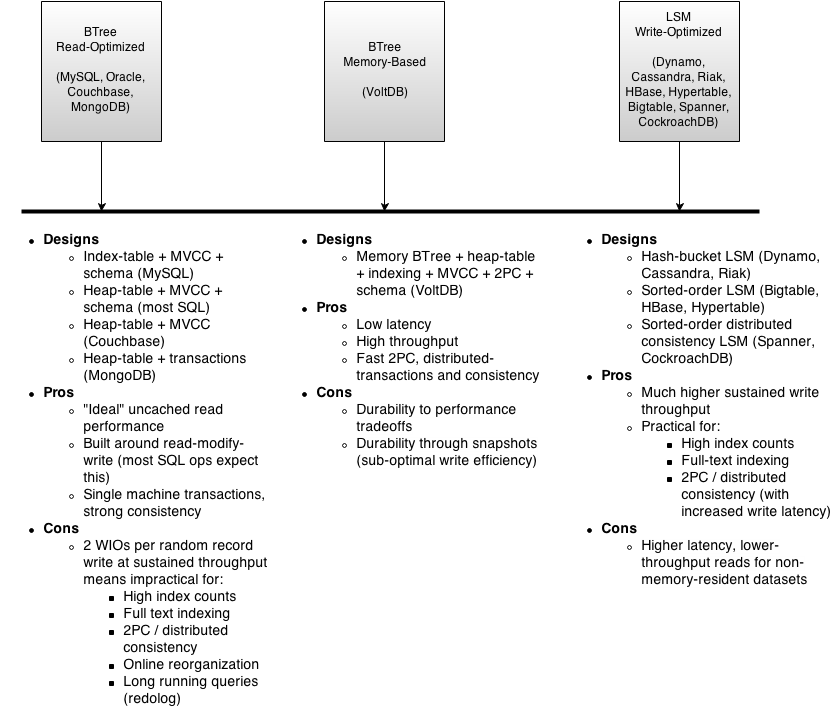
Given this information, data-stores can be sliced by their sorted-order storage algorithm selection. Btree stores are read-optimized (Oracle, SQLServer, Postgres, SQLite2, MySQL, MongoDB, CouchDB), hybrid stores are read-optimized with better write-throughput (Tokutek MySQL/MongoDB), while LSM-variants are write-optimized (HBase, Cassandra, SQLite3/LSM, CockroachDB).
Architecture
CockroachDB implements a layered architecture, with various subdirectories implementing layers as appropriate. The highest level of abstraction is the [SQL layer][5], which depends directly on the structured data API. The structured data API provides familiar relational concepts such as schemas, tables, columns, and indexes. The structured data API in turn depends on the [distributed key value store][7] ([kv/][8]). The distributed key value store handles the details of range addressing to provide the abstraction of a single, monolithic key value store. It communicates with any number of [RoachNodes][9] ([server/][10]), storing the actual data. Each node contains one or more [stores][11] ([storage/][12]), one per physical device.
Each store contains potentially many ranges, the lowest-level unit of key-value data. Ranges are replicated using the [Raft][2] consensus protocol. The diagram below is a blown up version of stores from four of the five nodes in the previous diagram. Each range is replicated three ways using raft. The color coding shows associated range replicas.
Client Architecture
RoachNodes serve client traffic using a fully-featured SQL API which accepts requests as either application/x-protobuf or application/json. Client implementations consist of an HTTP sender (transport) and a transactional sender which implements a simple exponential backoff / retry protocol, depending on CockroachDB error codes.
The DB client gateway accepts incoming requests and sends them through a transaction coordinator, which handles transaction heartbeats on behalf of clients, provides optimization pathways, and resolves write intents on transaction commit or abort. The transaction coordinator passes requests onto a distributed sender, which looks up index metadata, caches the results, and routes internode RPC traffic based on where the index metadata indicates keys are located in the distributed cluster.
In addition to the gateway for external DB client traffic, each RoachNode provides the full key/value API (including all internal methods) via a Go RPC server endpoint. The RPC server endpoint forwards requests to one or more local stores depending on the specified key range.
Internally, each RoachNode uses the Go implementation of the CockroachDB client in order to transactionally update system key/value data; for example during split and merge operations to update index metadata records. Unlike an external application, the internal client eschews the HTTP sender and instead directly shares the transaction coordinator and distributed sender used by the DB client gateway.
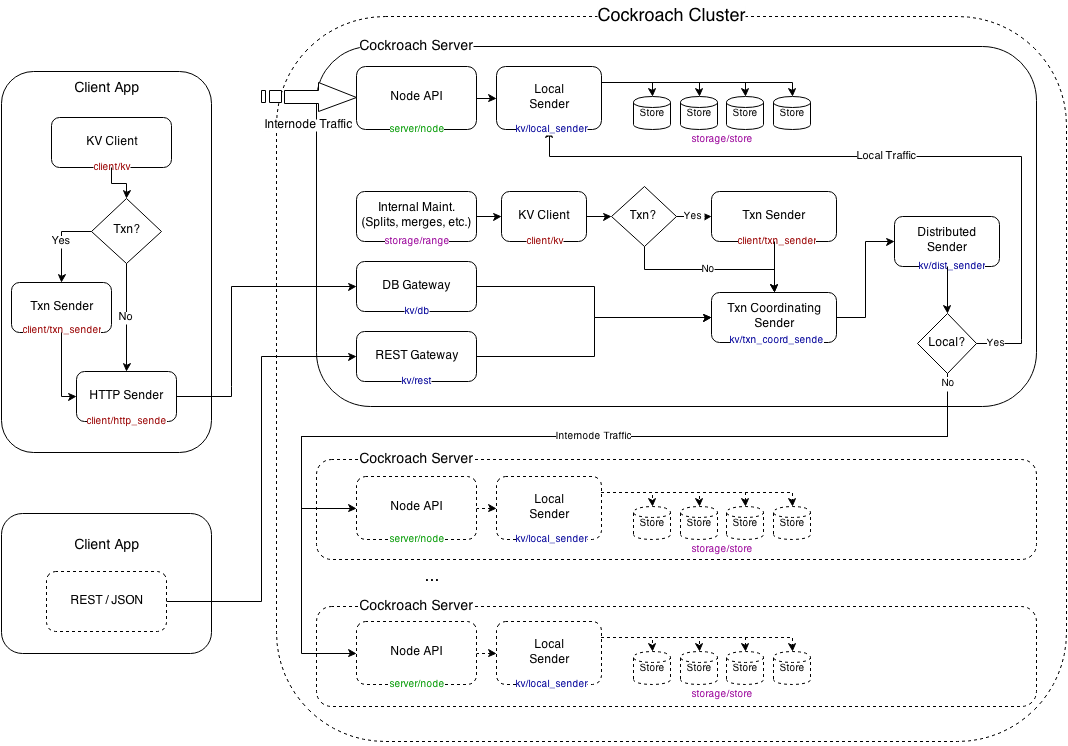
[0] http://rocksdb.org/ [1] https://github.com/google/leveldb [2] https://ramcloud.stanford.edu/wiki/download/attachments/11370504/raft.pdf [3] http://research.google.com/archive/spanner.html [4] http://research.google.com/pubs/pub36971.html [5] https://github.com/cockroachdb/cockroach/tree/master/sql [7] https://godoc.org/github.com/cockroachdb/cockroach/kv [8] https://github.com/cockroachdb/cockroach/tree/master/kv [9] https://godoc.org/github.com/cockroachdb/cockroach/server [10] https://github.com/cockroachdb/cockroach/tree/master/server [11] https://godoc.org/github.com/cockroachdb/cockroach/storage [12] https://github.com/cockroachdb/cockroach/tree/master/storage
下面是一些F1的资料
[13] http://www.leafonsword.org/google-f1/
blog comments powered by Disqus